Why your interview rubric isn't getting opened during interviews
Most interview rubric advice fixes the doc and ignores the workflow. Here is why the rubric and the evidence have to live in the same place.

AI summary
- Most interview rubric advice tells you to pick five competencies, build a 1-5 scale, and add behavioral anchors. The advice is fine. The problem is one nobody on the SERP names. The rubric and the evidence live in different tabs, and a rubric in a different tab from the recording is a rubric nobody opens during the call.
- The teams that screen well treat the rubric the way their engineering team treats a Linear issue template. It's not a doc. It's a piece of process infrastructure that ships with the work, gets scored against the actual evidence, and stays current because the workflow makes updates the path of least resistance.
- The fix isn't a better template. It's binding the rubric you wrote at intake to the candidate response you're reviewing, so every score has the evidence attached and the debrief turns into an audit instead of a memory contest.
The rubric was good. You spent a Sunday afternoon on it. Six competencies, a 1-to-5 scale with behavioral anchors, a calibration session on the Tuesday after, the whole shape every guide tells you to build. You sent it to the four interviewers on the Customer Success Lead loop with a Loom walkthrough and a note that said please use this. You felt, briefly, like a person who had solved hiring.
Three weeks later you sat in the debrief. Four interviewers. Same candidate. One person said she was “clearly the strongest of the bunch.” Another said she “seemed fine, hard to compare.” A third had not opened the rubric at all because the rubric was in Notion, the recording was in a Zoom share link, the resume was in the ATS, and he had picked whichever loaded fastest. The hiring manager looked at the ceiling for a long time and asked whether you were actually moving her forward or not.
Here is the thing none of the rubric guides will say. Your interview rubric isn’t failing because it’s the wrong template. It’s failing because it lives in a different tab than the candidate. A rubric the interviewer has to switch tabs to find is a rubric the interviewer doesn’t open. The teams that screen well stopped treating the rubric as a doc years ago. They treat it the way their engineering team treats a Linear issue template, and that is the difference the SERP refuses to draw.
Most interview rubric advice solves the wrong half of the problem
The standard playbook isn’t wrong. It’s solving the wrong scale of problem.
Where the rubric playbook came from
When the modern rubric got its current shape, the bottleneck was interviewer disagreement. The fix was a shared scoring rubric so two people watching the same candidate would arrive at the same score. Pick five to eight role-specific competencies. Map a question to each. Build a 1-to-5 scale. Add behavioral anchors so a 3 means the same thing to everyone. Calibrate the team in a mock-scoring session. The steps still work for the problem they were designed to solve.
That is not the problem you have. Your interviewers can probably agree on what a 4 means, in the abstract. They are not scoring the candidate at a 4. They are scoring her at “yeah she seemed fine,” because by the time they score, the rubric is two tabs and a Notion login away from the artifact they are scoring. That is the failure mode behind most of the common interview mistakes you see in a debrief.
What the rubric guides won’t talk about
Every one of the top ten posts on interview rubrics ends with a free template and a calibration tip. None ask whether the rubric will get opened during the call. None ask what month four looks like, when the role has shifted and the rubric still reads the way it did at intake. None treat the rubric as a living artifact that travels with the evidence. The most popular guide on the internet treats it as a worksheet you fill out once and reference later. That is not how good hiring decisions work, and not how anyone you respect at your own company runs anything else.
What gets hidden when the rubric and the evidence live in different tabs
In a four-interviewer loop, the rubric is opened by less than half the panel.
The 47 percent rubric-open rate
The pattern across hiring teams we work with is consistent. The hiring manager opens the rubric because she wrote it. One of the three interviewers opens it because he reads the prep doc. The other two skim it on the way to the call, take their own notes, and score from memory four hours later in a Slack DM that says “she felt strong to me.” The reason is structural. The rubric is in Notion. The resume is in the ATS. The recording is in a Zoom link in a different Slack thread. Every interviewer who wants to score against the rubric has to keep three tabs open, and on a Tuesday afternoon between two other meetings, they don’t.
The cost shows up in two places. The debrief turns into a comparison of impressions, which is the failure mode the rubric was supposed to prevent. The rubric itself stops getting maintained, because the team has already implicitly agreed it isn’t really how the decision gets made.
Two debriefs, same role
Picture two debriefs. In the first, the four interviewers walk in with notes and impressions. The hiring manager asks how everyone felt. Someone says she was strong on customer empathy. Someone else says she was fine on technical depth, hard to tell. The hiring manager nods, makes the call. Two months later the hire is struggling on technical depth and nobody can remember whether anyone actually probed it.
In the second debrief, the four interviewers walk in with the rubric filled out per criterion, with timestamped clips for each score. The hiring manager asks, criterion by criterion, what the evidence said. Customer empathy, 4 out of 5, here is the 22-second clip where she described coaching a junior CSM through a difficult renewal. Technical depth, 3 out of 5, here is the moment the resolution felt thinner than the role needs. The decision still belongs to humans. The basis is on the table, with interview feedback that points at evidence, not at impressions.
The difference between the two debriefs is not the rubric. It is whether the rubric and the evidence live in the same place.
Engineering teams already solved this with the Linear issue template
Your engineering team would never let a feature ship without a tracked ticket. They would not even consider it.
What a Linear issue actually is
A Linear issue is not a doc. It is a structured artifact that follows the work from filed to shipped. Title. Acceptance criteria. Labels. Status. Linked PRs. Comments. When the work moves, the ticket moves with it. When the criteria change, the change is in the history. When the work ships, the resolution is documented inline. The artifact is the ticket.
That structure exists because the workflow makes structured behavior the path of least resistance. Filing a ticket is faster than not filing one, because the team has agreed that work without a ticket is invisible. The artifact and the work are bound together by the tool, and the discipline emerges from the binding.
Why hiring rubrics rot and Linear issues don’t
The same companies running Linear religiously for engineering let their hiring rubrics live in a Notion page nobody opens. The rubric is structurally identical to a Linear issue template. What it does not have is the binding to the work. The candidate’s response is never attached to the rubric, and the score is never recorded against the response. The rubric is not failing because hiring people are less rigorous than engineers. It is failing because the workflow does not make rigor the easy path.
A hiring rubric should be a Linear issue for the candidate. Criteria are the acceptance criteria. Responses are the evidence in the comments. The score is the status. The debrief is the merge review.
Four properties of a rubric your team will actually open
Once you stop thinking of the rubric as a doc, the design rules change. Four properties separate the rubrics interviewers open from the ones they bookmark.
Criteria defined once, at intake, used everywhere
The criteria the recruiter writes at the intake call with the hiring manager score the candidate at every downstream stage. One set of criteria, set once, used four times. When the role shifts in month four, you change them in one place and every downstream artifact updates. A rubric you maintain in Notion will not stay tailored. A rubric bound to the role record will.
Scoring is tied to specific evidence
“Customer empathy, 4 out of 5” is not a score. “Customer empathy, 4 out of 5, the 22-second segment where she described the renewal coaching” is a score. The first is an impression. The second is auditable. The difference is whether the rubric forces the interviewer to anchor the number to evidence in the same surface they are scoring in.
One review surface, not three
The rubric, the response, and the score live in the same view. Not a Notion doc plus a Zoom replay plus an ATS field. The interviewer opens the candidate, sees the criteria, watches the response, and scores in the same place. The single-surface workflow is what your engineering team takes for granted on every Linear ticket and what your hiring team rarely gets.
Updates are as cheap as a Linear comment
A rubric that costs an hour to update will not get updated. A rubric that costs ten seconds will get updated every week. The threshold matters more than the template. If a recruiter cannot update the rubric in less time than training a hiring manager on a new question takes, the rubric is not infrastructure.
”But my interviewers want flexibility, not a rigid scorecard”
This is the version of the objection most worth taking seriously.
Real interviews are conversations. A 47-row scoring matrix turns the interview into a checklist exercise, the senior end of the panel refuses to fill it out, the conversation goes flat, and the data arrives in a form that does not predict performance.
Two things are true about that argument.
Where the objection is right
A 47-row scoring matrix is not a rubric. It is a punishment for being on the panel. If your “rubric infrastructure” turns into twelve numerical scores per interviewer per candidate, you have rebuilt the worksheet model with extra steps, and the panel will route around it. A rubric that competes with the conversation will lose.
Where it stops being right
It stops being right when “rigid” gets confused with “structured.” The rubrics that win interviewer adoption are not the longest. They are the ones where filling out the rubric is faster than not filling it out, because the rubric is bound to the artifact the interviewer is already looking at. Five criteria, anchored to specific moments in a structured screening response, reviewed in the same surface as the response. The total cost is lower than the cost of taking notes in a separate doc, which is what most interviewers do anyway. The flexibility complaint is almost always a complaint about uncalibrated friction, not about structure.
A working week looks different when the rubric ships with the evidence
Back to the Customer Success Lead loop. Same panel, same week. Different setup.
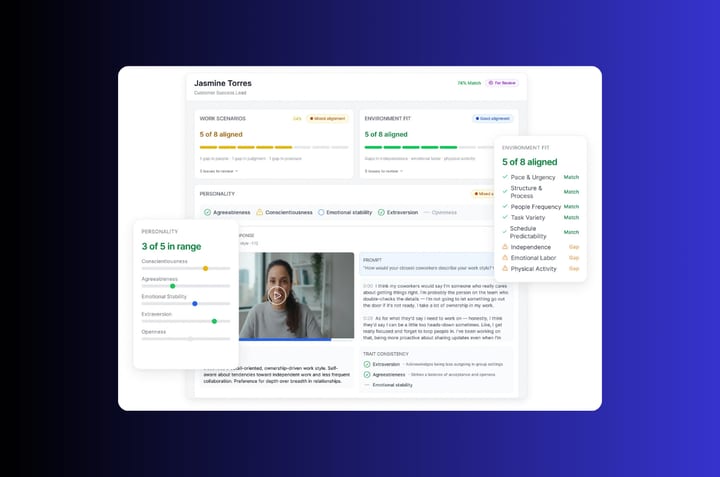
The candidate side
The criteria you set at the intake call become the criteria the role is screened against. One source of truth. The careers page funnels into a single Position Link. The candidate taps it on a phone, sees a 90-second welcome from the hiring manager, and answers four screening questions on video. Total candidate time, eight to twelve minutes. Resumes go through Truffle’s scoring against the criteria you wrote at intake. AI Match shows how closely each response aligns with each criterion, broken down per question. At the top of the dashboard, Candidate Shorts compress each candidate’s most revealing moments into about thirty seconds. The rubric you wrote on Sunday afternoon is the spine of the screening surface. It is not a doc. It is the dashboard.
The recruiter side
Tuesday morning, you open a list of candidates ranked by AI Match against the rubric. Each criterion is hyperlinked to the moment in the response that produced the score. You forward the eight strongest to the hiring manager and interviewers, with criterion-level scores attached and response evidence one click away. The panel does not switch tabs. They open one surface, see the rubric and the candidate together, and score in the same place. The live interview becomes the four or five questions the rubric flagged as low-confidence. Collaborative evaluation lets each interviewer score independently before the debrief so consensus comes from evidence, not from whoever speaks first.
The debrief is fifteen minutes. Where the panel agrees, they move on. Where they disagree, everyone is looking at the same clip. The decision and the basis are documented in the same surface where the next candidate review will happen.
The rubric isn’t a doc. It’s the spine of the decision.
Two months later, you open the rubric for the next Customer Success Lead role. Two of the criteria have been edited based on what you learned from the first hire. The edits live next to a worked example of what each score level looked like in real candidate footage. The hiring manager who used to skim the rubric on the way to the call now writes the first draft himself, because the cost of writing is lower than the cost of explaining what he wants in a meeting.
This is what the engineering teams in your own company take for granted. A feature does not ship without a tracked ticket. The ticket has acceptance criteria. The criteria are scored against evidence. The artifact and the work are bound together. Hiring is the last corner of the company where the same standard has not arrived, and the rubric guides on the SERP are still arguing about templates.
Build the rubric the way your engineering team builds an issue template, and your interviewers will start opening it.
Frequently asked questions about interview rubrics
What is the difference between an interview rubric and an interview scorecard?
The terms are often used interchangeably. The useful distinction is that the rubric defines what each score level means (with behavioral anchors), and the scorecard is where the scores get recorded. The version you actually want has both, bound to the candidate’s response evidence in the same view.
How many criteria should an interview rubric have?
Five to eight is roughly right. Past eight, interviewers skip rows. Below five, you are not differentiating candidates well enough. What matters more than the count is whether each criterion has a specific question that tests it and a piece of evidence that anchors the score.
What rating scale works best for an interview rubric?
A 1-to-5 scale with behavioral anchors is most common. Some teams use 1-to-4 to force interviewers off the middle option. Either works if every score level has an anchor concrete enough to disagree with.
How do you keep an interview rubric from going stale?
Bind it to the same surface the team uses to review candidates, and make updates cheaper than ignoring them. A rubric maintained in a separate Notion doc will rot inside three months. A rubric maintained inside the review surface stays current because updating it is the path of least resistance.
Should the same rubric be used for every stage of the interview process?
The criteria should be consistent. The depth at which each criterion gets scored varies by stage. The screening response might score four of seven criteria at low fidelity. The live interview probes the two or three the screening flagged as low-confidence. One rubric, scored in successive passes, with each stage adding evidence to the same record.